
Chapter 05 데이터 가공하기
| 05-1 dplyr 패키지 |
- dplyr 패키지
- plyr 패키지 + C++언어 : 사용자 친화적으로 빠르게 데이터 프레임을 조작할 수 있는 패키지
- dplyr 패키지 설치 및 로드하기
# dplyr 패키지 설치 및 로드하기
install.packages(“dplyr”)
library(dplyr)

- 데이터 추출 및 정렬하기
® 행 추출하기 : filter() 함수
| filter(“원시 데이터”, 조건) |


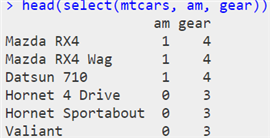
® 열 추출하기 : select() 함수
| select(“원시 데이터”, 조건) |

® 정렬하기 : arrange() 함수
| arrange(“원시 데이터”, 조건) |


- 데이터 추가 및 중복 데이터 제거하기
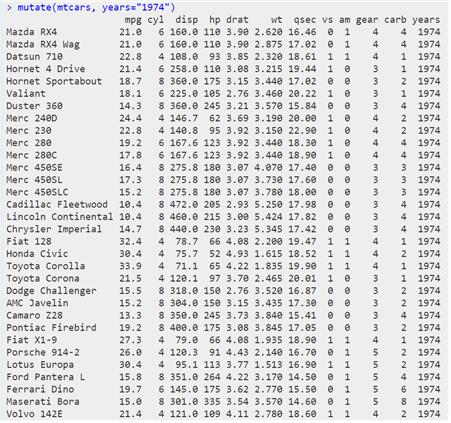
® 열 추가하기 : mutate() 함수
| mutate(“원시 데이터”, 추가할 변수 이름 = 조건1, ...) |
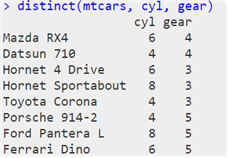
® 중복 값 제거하기 : distinct() 함수
| distinct(“원시 데이터”, 열 이름) |

- 데이터 요약 및 샘플 추출하기
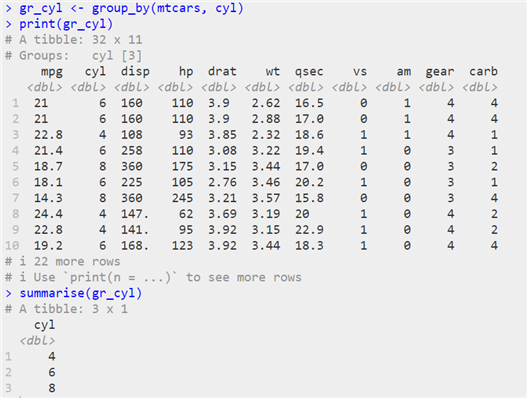
® 데이터 전체 요약하기 : summarise() 함수
| summarise(“원시 데이터”, 변수이름 = 기술통계 함수(), ...) |

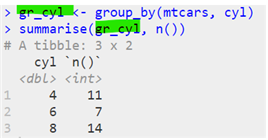
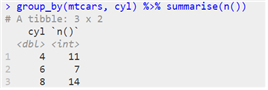
® 그룹별로 요약하기 : group_by() 함수
| group_by(“원시 데이터”, 열 이름) |

| <tibble> tidy data에 최적화된, data.frame과 유사한 객체 <dbl> double. tibble 형태의 데이터의 변수가 실수형태라는 뜻. <int> integer. tibble에서 해당 변수 값을 갖는 데이터의 수 |
| <chr> 문자형(character) <int> 정수(integer) == 빈도 수 <dbl> 더블(double) <date> 날짜(date) <time> 시간(time) <dttm> 날짜와 시간(date-time) <lgl> 논리값. 조건에 맞으면 TURE, 그렇지 않으면 FALSE 반환 +lbl 변수의 값에 부여된 라벨 값이 추가되어 있음을 표시 |
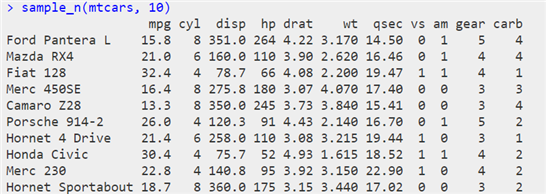
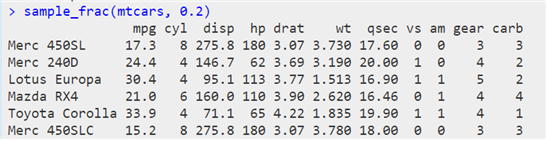
® 샘플 추출하기 : sample_n(), sample_frac() 함수
| sample(“원시 데이터”, 조건) |
| sample_n(“원시 데이터”, 샘플의 크기) |
| sample_frac(“원시 데이터”, 샘플의 크기) |
- 파이프 연산자 : %>%
- 새로운 변수를 생성하지 않고 이어서 함수를 적용할 수 있다.
| 데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트 |
| 05-2 데이터 가공하기 |
- 데이터 가공
= 데이터 전처리(data preprocessing), 데이터 핸들링(data handling), 데이터 마트(data mart)
- 필요한 데이터 추출하기
(1) 사용할 변수를 선택하는 방식
| 데이터 이름 %>% select(“원시 데이터”, 조건) |
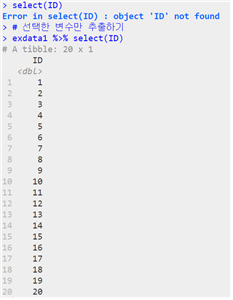

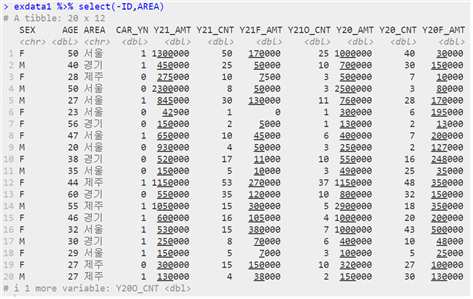
(2) 원하는 조건 값에 맞는 데이터를 추출하는 방식
| 데이터 이름 %>% filter(“원시 데이터”, 조건) |
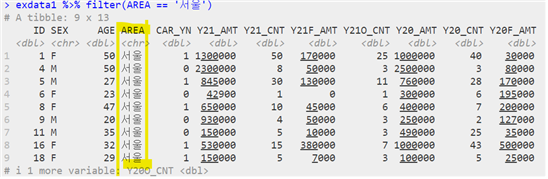
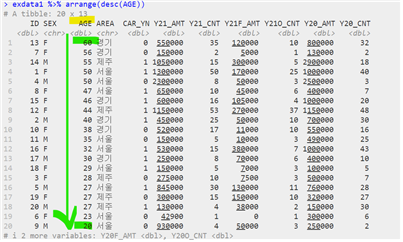
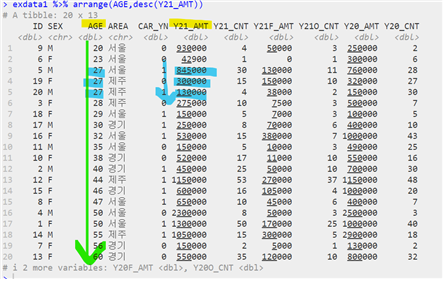
- 데이터 정렬하기
| 데이터 이름 %>% arrange(“원시 데이터”, 조건) |
| # 오름차순 정렬하기 # 내림차순 정렬하기 # 중첩 정렬하기 [& 연산자를 사용하지 않음] |
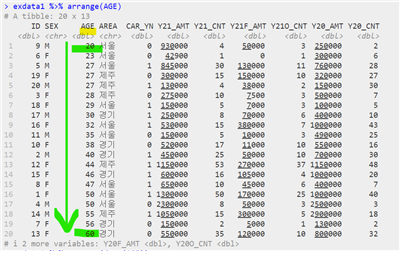
- 데이터 요약하기
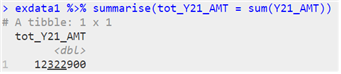
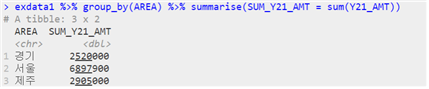
| 데이터 이름 %>% summarise(“원시 데이터”, 조건) |
- 데이터 결합하기
(1) 세로 결합 (행 추가)
| bind_rows(“원시 데이터”, 조건) |
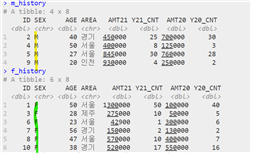
(2) 가로 결합 (열 추가)
| left_join(첫 번째 테이블, 두 번째 테이블, by = “조인키”) | A⋂Bc |
| right_join(첫 번째 테이블, 두 번째 테이블, by = “조인키”) | Ac⋂B |
| inner_join(첫 번째 테이블, 두 번째 테이블, by = “조인키”) | A⋂B |
| full_join(첫 번째 테이블, 두 번째 테이블, by = “조인키”) | A⋃B |

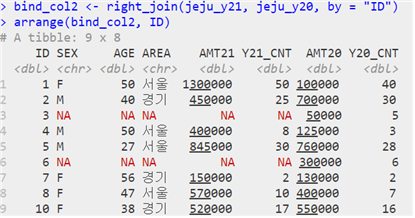
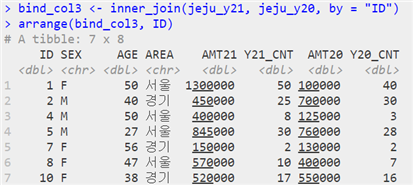
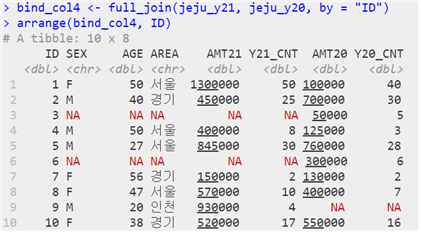
| 05-3 데이터 구조 변형하기 |
- reshape2 패키지
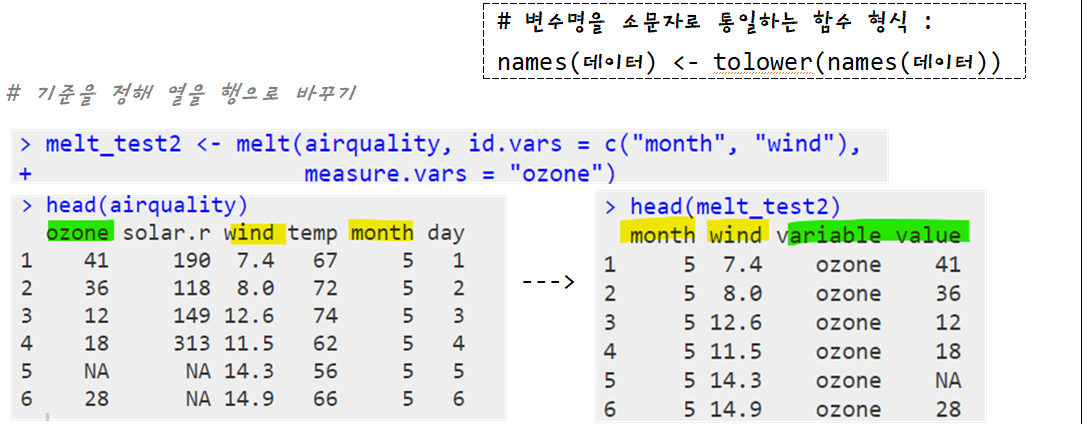
- melt() 함수 : 열이 긴 형태의 데이터 -> 행이 긴 형태
- cast() 함수 : 행이 긴 형태의 데이터 -> 열이 긴 행태

- melt() 함수
| melt(데이터, id.vars = “기준 열”, measure.vars = “변환 열”, 옵션1, ...) |
| * 기타 옵션 na.rm : 결측치 포함 여부 (FALSE = 결측치 포함/ TRUE = 결측치 미포함) value.name : 행으로 바꾸고 싶은 열 이름 |
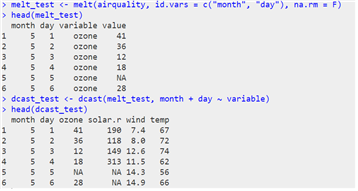
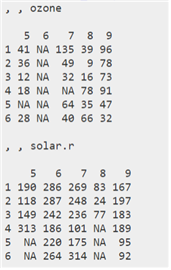
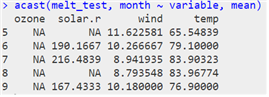
- cast() 함수
| cast() |
| acast(데이터, 기준열 ~ 변환 열, 분리기준 열) |
| dcast(데이터, 기준 열 ~ 변환 열) |
| 데이터를 변형(행->열)하여 벡터, 행렬, 배열 형태로 반환 |
| 데이터를 변형(행->열)하여 데이터 프레임 형태로 반환 |
| # dcast()함수로 melt()함수를 역으로 돌리기 # acast() 함수로 데이터 분리하기 |
| # cast 함수로 평균 요약하기 |

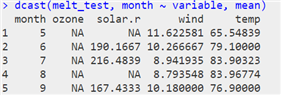
- 함수 정리
melt(data, # 원본 데이터
id, # 고정 컬럼
measure.var) # stack처리 할 컬럼(생략 시 id컬럼 제외 모든 컬럼)
dcast(data, # 원본 데이터
formula, # 행 고정 ~ unstack 처리 컬럼
fun.aggregate = NULL, # 데이터 축약 시 사용 그룹,결합 함수 (default:length)
margins = NULL, # 부분합 출력 시 TRUE
value.var = guess_value(data)) # value 컬럼 지정. 생략 가능
(default:마지막컬럼)
# 고정시키고자하는 컬럼(name), 분리 컬럼(info), 값을 담고자하는 대상(value)
> dcast(d1, name ~ info) # 맨 마지막 컬럼(value)을 자동으로 지정
| 05-4 데이터 정제하기 |
- 결측치와 이상치
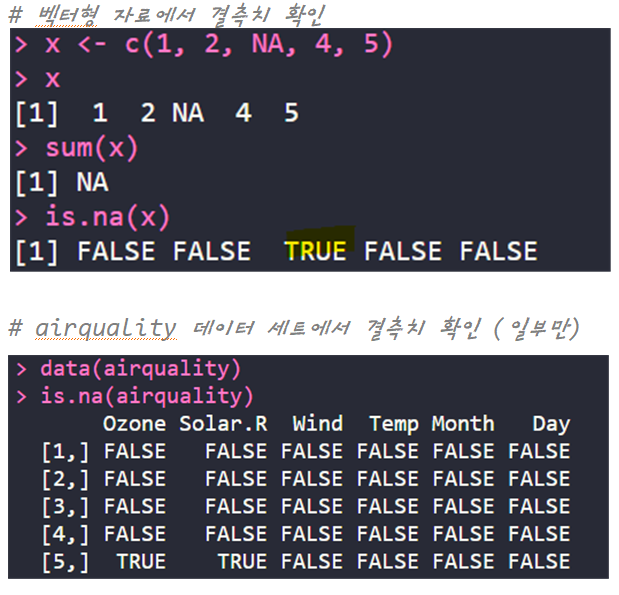
- 결측치 : 원시 데이터에서 값이 누락된 경우. Not Available = NA (파이썬에서는 NULL)
- 이상치 : 원시 데이터에서 일반적인 값보다 편차가 큰 경우
- 결측치와 이상치는 오류를 발생시키거나 분석결과를 왜곡할 수 있다. ==> 데이터 정제 필요
- 결측치나 이상치를 처리할 방식을 판단하는 것은 분석가에 따라, 분석 방식에 따라 상이할 수 있다.
- 결측치 처리
| 결측치 확인 | is.na() | 결측치가 있으면 TRUE를 반환 |
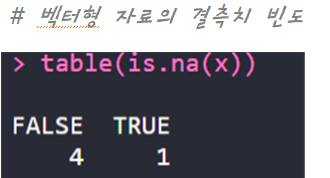
| table(is.na()) | 결측치의 빈도를 확인 (TRUE와 FALSE의 빈도를 각각 구할 수 있음) |
|
| sum(is.na()) | 데이터 세트에 결측치가 총 몇 개인지 확인 | |
| colSums(is.na()) | 각 컬럼의 결측치 개수를 확인 | |
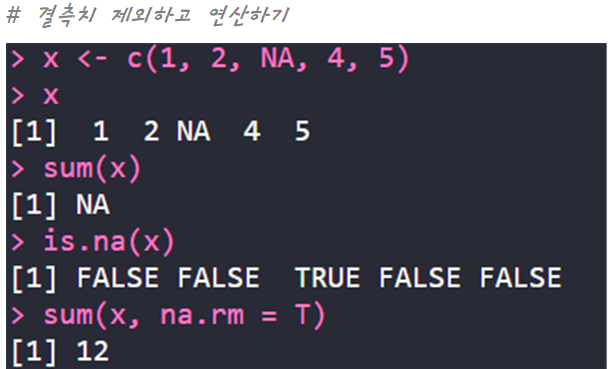
| 결측치 제외 | na.rm = T [옵션] | 결측치 제외하고 연산 |
| 결측치 제거 | na.omit() | 결측치가 있는 행 전체를 데이터 세트에서 제거한 후 연산 |
| 결측치 대체 | 변수명[is.na(변수명)] <- 대체한 후의 값 | 데이터의 결측치를 다른 값으로 대체 (ex. 결측치를 0으로 대체할 경우 : ~~ <- 0) |


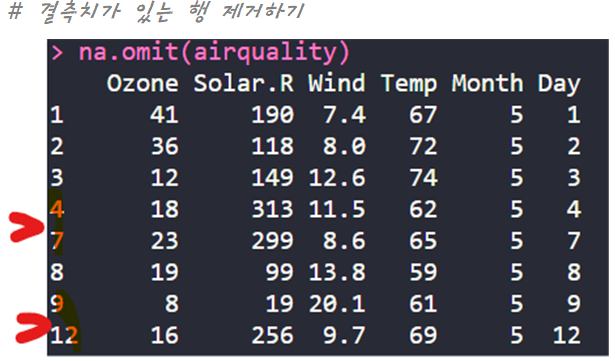
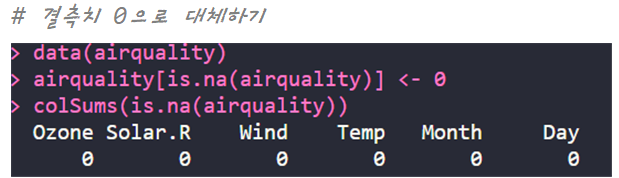
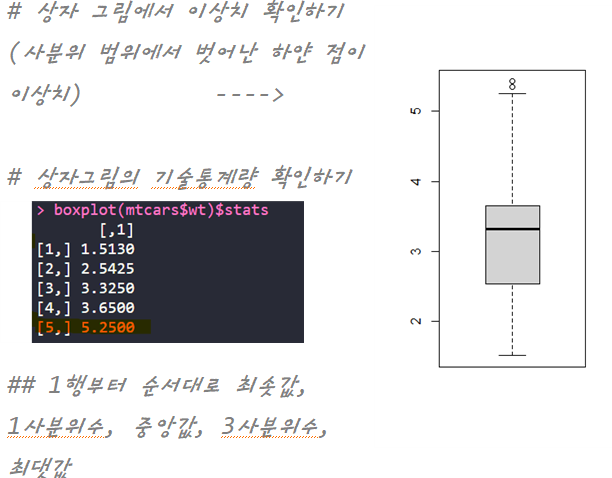
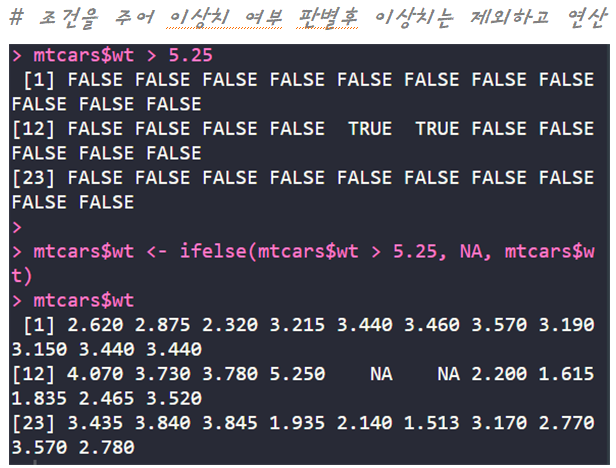
| 혼공 미션 |
- 기본미션 (파이프 연산자를 사용하여 새로운 데이터 세트 만들기)
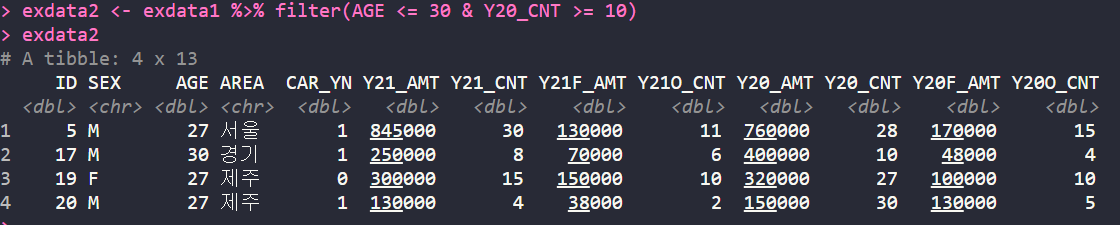
- 선택미션 (엑셀 데이터 불러오기 + 파이프 연산자 연이어 사용)
# p261 예제 4번
>
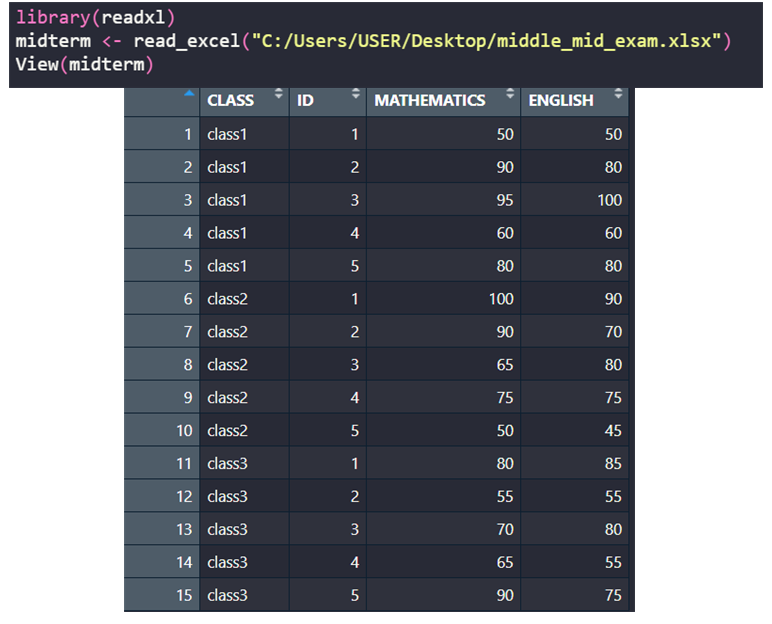
> library(readxl)
> midterm <- read_excel("C:/Users/USER/Desktop/middle_mid_exam.xlsx")
> View(midterm)
>
> library(dplyr)
> library(reshape2)
>
> ## mathmatics dataset
>
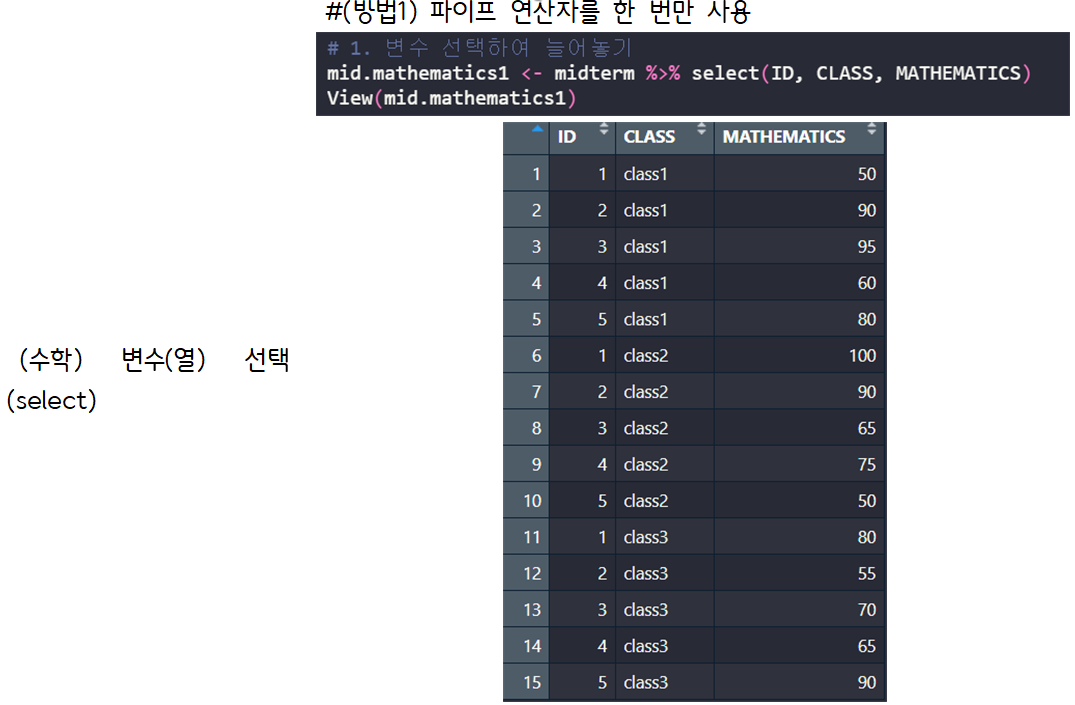
> #(방법1) 파이프 연산자를 한 번만 사용
> mid.mathematics1 <- midterm %>% select(ID, CLASS, MATHEMATICS) # 1. 변수 선택하여 늘어놓기
> View(mid.mathematics1)
>
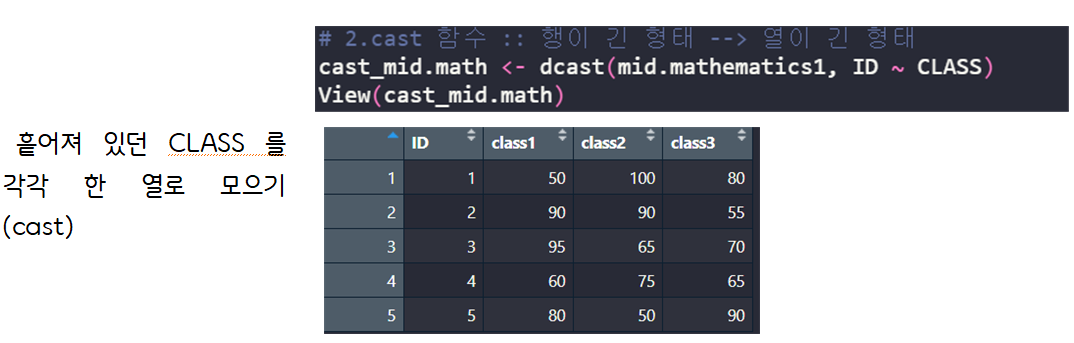
> cast_midmath <- dcast(mid.mathematics1, ID ~ CLASS) # 2.cast 함수 :: 행이 긴 형태 --> 열이 긴 형태
Using MATHEMATICS as value column: use value.var to override.
> View(cast_mid.math)
>
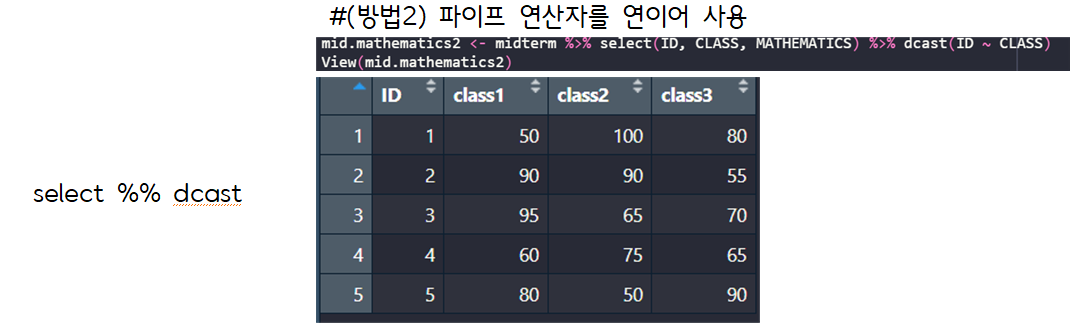
> #(방법2) 파이프 연산자를 연이어 사용
> mid.mathematics2 <- midterm %>% select(ID, CLASS, MATHEMATICS) %>% dcast(ID ~ CLASS)
Using MATHEMATICS as value column: use value.var to override.
> View(mid.mathematics2)
>
>
> ## english dataset
>
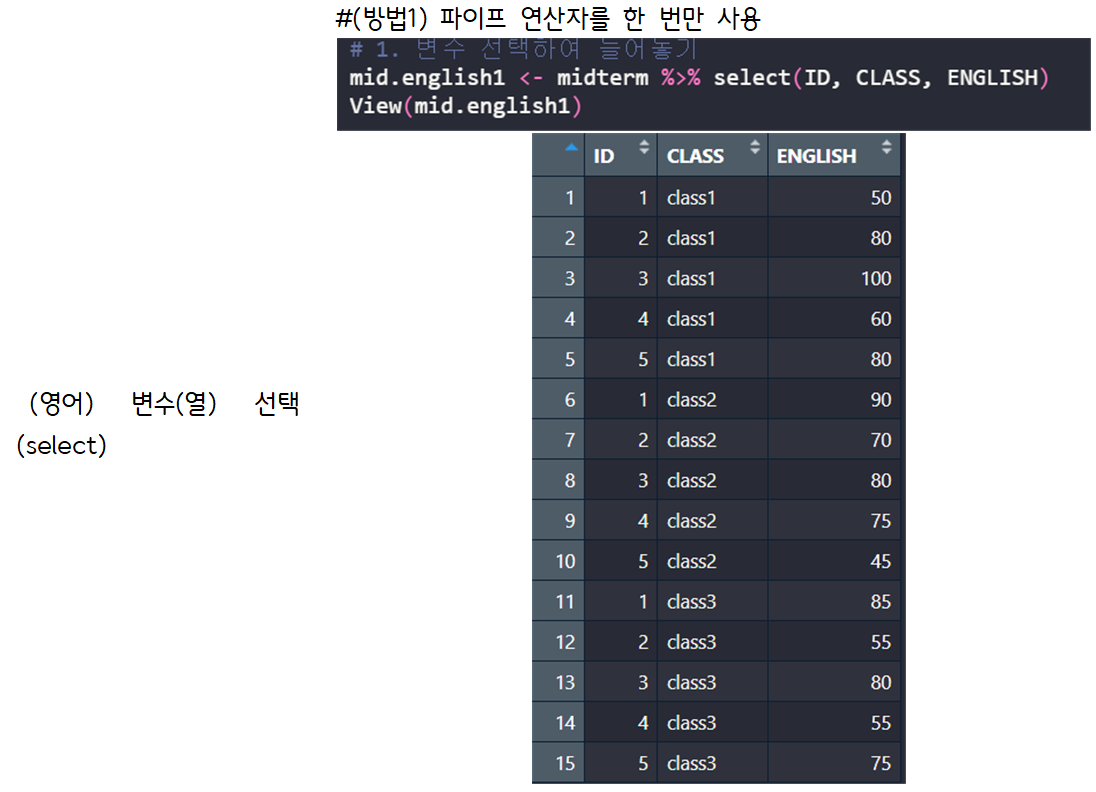
> #(방법1) 파이프 연산자를 한 번만 사용
> mid.english1 <- midterm %>% select(ID, CLASS, ENGLISH) # 1. 변수 선택하여 늘어놓기
> View(mid.english1)
>
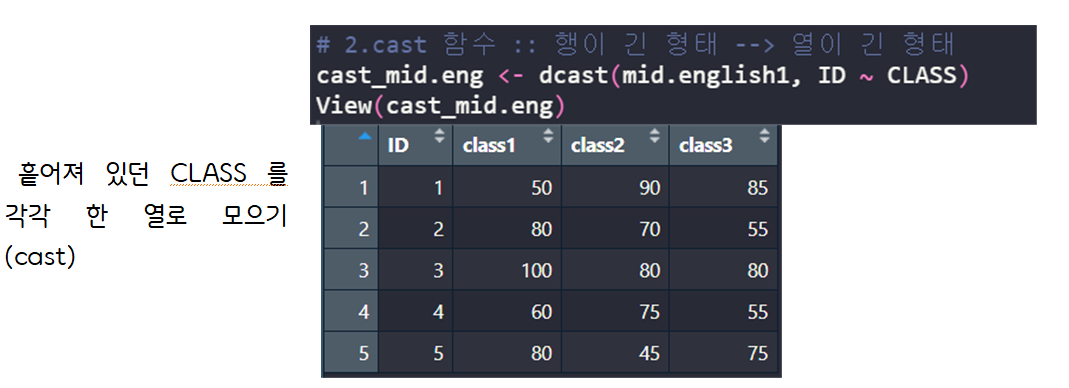
> cast_mid.eng <- dcast(mid.english1, ID ~ CLASS) # 2.cast 함수 :: 행이 긴 형태 --> 열이 긴 형태
Using ENGLISH as value column: use value.var to override.
> View(cast_mid.eng)
>
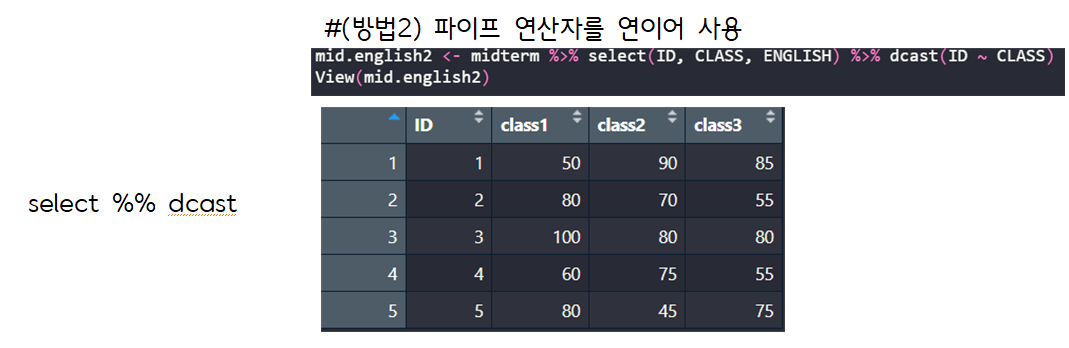
> #(방법2) 파이프 연산자를 연이어 사용
> mid.english2 <- midterm %>% select(ID, CLASS, ENGLISH) %>% dcast(ID ~ CLASS)
Using ENGLISH as value column: use value.var to override.
> View(mid.english2)
>
| 정리본 pdf |
'프로그래밍 > R 공부' 카테고리의 다른 글
| [혼공학습단 10기] 혼자 공부하는 R 데이터 분석 Chapter 06 (2) | 2023.08.20 |
|---|---|
| (코드 오류와 해결 기록) dcast() : Aggregation function missing: defaulting to length (0) | 2023.07.19 |
| [혼공학습단 10기] 혼자 공부하는 R 데이터분석 Chapter 04 (8) | 2023.07.12 |
| [혼공 학습단 10기] 혼자 공부하는 R 데이터분석 Chapter 03 (0) | 2023.07.11 |
| [혼공학습단 10기] 혼자 공부하는 R 데이터분석 Chapter 02 (0) | 2023.07.05 |